Random Forest Algorithms: A Complete Guide


[ad_1]
Random forest is a flexible, easy to use machine learning algorithm that produces even without hyper-parameter tuning. It’s one of the most common because it can be used for both classification and regression tasks with little fussing needed on your end! In this post we’ll learn how random forests work as well as some other cool things they offer like diversity (they’re versatile).
Contents
- 1 What Is Random Forest?
- 2 How Random Forest Works
- 3 Real-Life Analogy
- 4 Feature Importance
- 5 Difference between Decision Trees and Random Forests
- 6 Important Hyperparameters
- 7 Advantages and Disadvantages of the Random Forest Algorithm
- 8 What is a Random Forest Classifier?
- 9 Random Forest Use Cases
- 10 Summary
What Is Random Forest?
Random forest is a technique that Ensembles many decision trees to make the best predictions. It does so by randomly combining individual models, and then optimizing their weights for accuracy using bagging methodologies employed within this process
Table of Contents
How Random Forest Works
Random forest is a type of supervised algorithm that uses decision trees in an ensemble to learn patterns. The “forest” it builds, the bagging method trains on many models for increased results.
Put simply: random forest builds multiple decision trees and merges them together to get a more accurate and stable prediction.
One big advantage of random forest is that it can be used for both classification and regression problems, which form the majority of current machine learning systems. Let’s look at random forest in classification, since classification is sometimes considered the building block of machine learning. Below you can see how a random forest would look like with two trees:
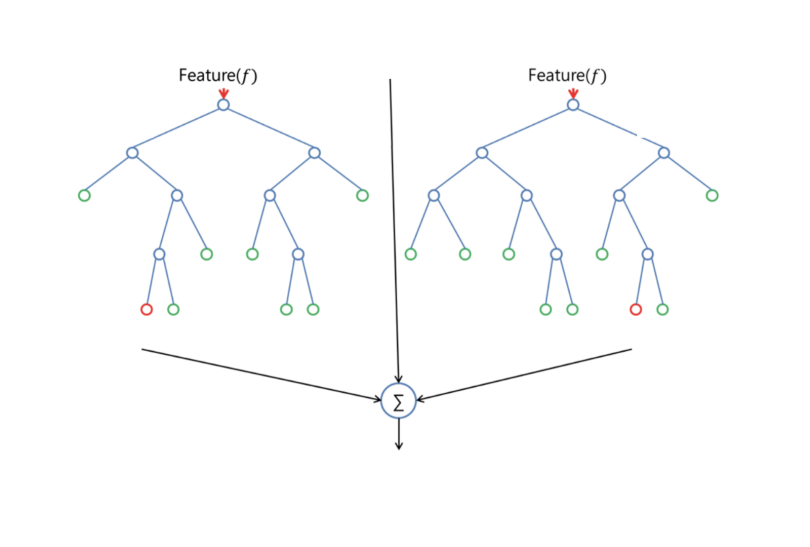
Random forest has nearly the same hyperparameters as a decision tree or bagging classifier. Fortunately, you don’t need to combine them because random forests are also used for regression tasks by using one of its regressors – algorithms that can handle both classification and regression problems at once!
Random forest is a machine learning technique that generally results in better models than those created with traditional techniques. It does this by adding additional randomness to the model while growing trees instead of searching for one most important feature and splitting nodes, which makes it more diverse as well.
Random forests can be used for making decisions in a more complex manner. In this method, only random subsets of features are taken into consideration by the algorithm and each node is split using various thresholds instead of searching for one optimum value that would determine its decision like normal trees do.
Real-Life Analogy
Andrew wants to decide where he’ll vacation during one year, so he asks people who know him best for suggestions. The first friend he seeks out is given advice based on the likes and dislikes of his past travels which will help him make a decision easily!
This is a typical decision tree algorithm approach. Andrew’s friend created rules to guide his decision about what he should recommend, by using Andrew’s answers.
Afterwards, Andrew starts asking more and more of his friends to advise him. They again ask different questions they can use in order for the algorithm recommend some places that will suit him best- which is an approach using random forests with typical characteristics found on such models.
This in-depth tutorial will help you to even better understand random forest algorithms
Feature Importance
Another great quality of the random forest algorithm is that it’s very easy to measure how important a feature will be when predicting scores. Sklearn provides an automated tool for this, which determines whether each potential value has any importance by looking at its impact across all trees in our forests’ decision stumps (hollowed out areas where branches are formed). The score computed from measurements like these can then yield more accurate estimations than those obtained just based off one variable alone – making them especially valuable during model creation or tuning!
If you don’t know how a decision tree works or what a leaf or node is, here is a good description from Wikipedia: ‘”In a decision tree each internal node represents a ‘test’ on an attribute (e.g. whether a coin flip comes up heads or tails), each branch represents the outcome of the test, and each leaf node represents a class label (decision taken after computing all attributes). A node that has no children is a leaf.'”
By looking at the feature importance you can decide which features to possibly drop because they don’t contribute enough (or sometimes nothing at all) for your model. This is important, as a general rule in machine learning -the more features there are on average per prediction process; then it becomes likely that overfitting will occur if too many irrelevant ones get included in an algorithm due to chance alone without any knowledge of what effects these particular inputs have had.
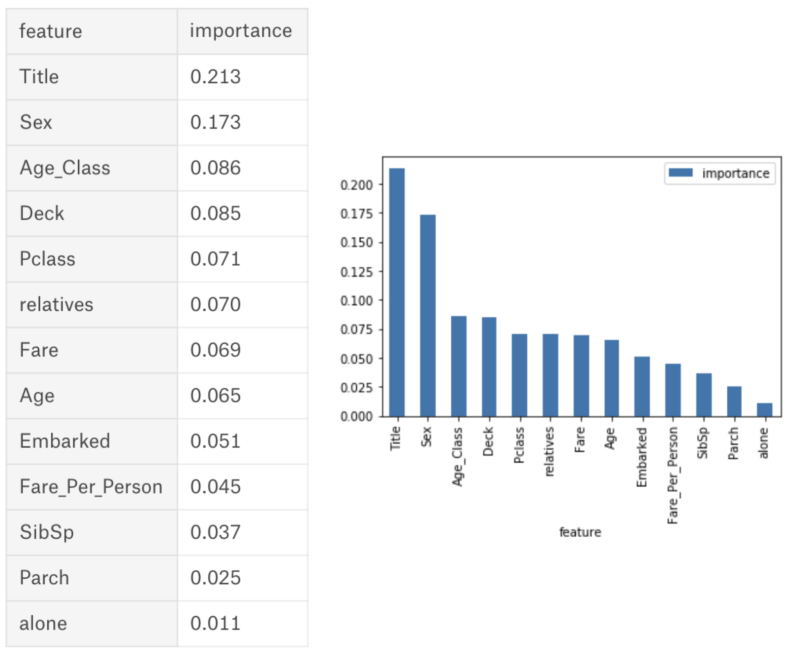
Below is a table and visualization showing the importance of 13 features, which I used during a supervised classification project with the famous Titanic dataset on kaggle. You can find the whole project here.

Difference between Decision Trees and Random Forests
While random forest is a collection of decision trees, there are some differences.
If you input a training dataset with features and labels into a decision tree, it will formulate some set of rules, which will be used to make the predictions.
In order to predict whether a person will click on an online advertisement, you might collect the ads that they have clicked in their past and some features about them. If these are put into decision trees with labels at each branching point then it would generate rules which help determine if this particular ad has any potential for generating traffic or not – but using random forests instead of just one tree leads us towards more accurate predictions because there’s no bias when building multiple models as opposedto having all decisions made by single algorithm alone .
A deep decision tree might suffer from overfitting. Random forests prevent this by creating random subsets and building smaller trees using those subset, but one downside is that it can take more time for these computations to complete depending on how many subtrees are generated in total with a single tree – so sometimes you want the larger forest instead!
Important Hyperparameters
The hyperparameters in random forest are either used to increase the predictive power of the model or to make the model faster. Let’s look at the hyperparameters of sklearns built-in random forest function.
1. Increasing the predictive power
Firstly, there is the n_estimators hyperparameter, which is just the number of trees the algorithm builds before taking the maximum voting or taking the averages of predictions. In general, a higher number of trees increases the performance and makes the predictions more stable, but it also slows down the computation.
Another important hyperparameter is max_features, which is the maximum number of features random forest considers to split a node. Sklearn provides several options, all described in the documentation.
The last important hyperparameter is min_sample_leaf. This determines the minimum number of leafs required to split an internal node.
2. Increasing the model’s speed
The n_jobs hyperparameter tells the engine how many processors it is allowed to use. If it has a value of one, it can only use one processor. A value of “-1” means that there is no limit.
The random_state hyperparameter makes the model’s output replicable. The model will always produce the same results when it has a definite value of random_state and if it has been given the same hyperparameters and the same training data.
Lastly, there is the oob_score (also called oob sampling), which uses a random forest cross validation method. In this case one third of all data isn’t used to train the model and can be used for evaluating its performance; these samples are called “out-of bag” or simply ‘bags’. It’s very similar in principle
to leave 1 out CV but almost no additional computational burden goes along with it at all!
Advantages and Disadvantages of the Random Forest Algorithm
One of the biggest advantages to using random forests is its versatility. It can be used for both regression and classification tasks, which are two very common problems in machine learning today; it’s also easy to view how important each input feature was towards making your prediction decision with relative precision thanks to this algorithm’s handy “ importance weights .” The default hyperparameters often produce good predictions so understanding them isn’t too daunting either!
One of the biggest problems in machine learning is overfitting, but most of the time this won’t happen thanks to the random forest classifier. If there are enough trees in the forest, the classifier won’t overfit the model.
What is a Random Forest Classifier?
The term “Random Forest Classifier” refers to the classification algorithm made up of several decision trees. The algorithm uses randomness to build each individual tree to promote uncorrelated forests, which then uses the forest’s predictive powers to make accurate decisions.
The main limitation of random forest is that a large number trees can make the algorithm too slow and ineffective for real-time predictions. In general, these algorithms are fast to train but quite slow when it comes time to create accurate predictions once they’re trained with more information from your input dataset. A quicker solution would be preferable in many situations where performance matters most – this doesn’t always apply though since sometimes you just need quick results without having every little detail correct upfront!
And, of course, random forest is a predictive modeling tool and not a descriptive tool, meaning if you’re looking for a description of the relationships in your data, other approaches would be better.
Random Forest Use Cases
The random forest algorithm is a powerful tool in the world of finance and trading. It’s used to determine customers’ likelihood for repayment on time as well as identifying fraudsters trying to scam banks out there, but it also comes into play when predicting future stock prices–which can be really handy if you’re looking at investing or day trading stocks!
In the healthcare domain it is used to identify the correct combination of components in medicine and to analyze a patient’s medical history to identify diseases.
Random forest is used in e-commerce to determine whether a customer will actually like the product or not.
Summary
To maximize the accuracy and efficiency of your model, you should start by training a random forest. This algorithm is simple yet effective for developing models quickly because it provides good indicators on what features are important to look at early in development process- not only does this save time but also helps with determining potential pitfalls before they happen!
Random forests are also very hard to beat performance wise. Of course, you can probably always find a model that can perform better, like a neural network for example, but these usually take more time to develop, though they can handle a lot of different feature types, like binary, categorical and numerical.
Overall, random forest is a (mostly) fast, simple and flexible tool, but not without some limitations.
Niklas Donges is an entrepreneur, technical writer and AI expert. He worked on an AI team of SAP for 1.5 years, after which he founded Markov Solutions. The Berlin-based company specializes in artificial intelligence, machine learning and deep learning, offering customized AI-powered software solutions and consulting programs to various companies.
[ad_2]
